Summary: During the forward pass, PyTorch’s autograd builds a graph for gradient computation. You can control how tensors are packed and unpacked with hooks. Different hooks can be registered to tensors and nodes for specific behaviors during gradient computation.
Note: The key thing to realize about the computational graph is that ithe direction of each edge refers to what happens in the forward pass.
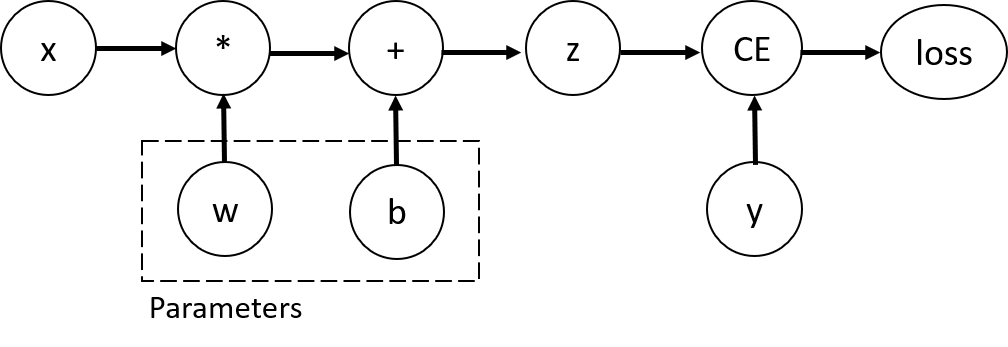
The parameters of the model have no dependencies because, during the forward pass, nothing operates on them. The loss function depends on everything else in the model because, during the forward pass, its value depends on the output (which depends on the parameters).
During the backward pass, the dependency chain is reversed (though at a data structure level, the DAG remains unchanged): in backpropagating the gradient of the loss, the parameters depend on everything and the loss function does not depend on anything.
Conceptually, autograd records a graph recording all of the operations that created the data as you execute operations, giving you a directed acyclic graph whose leaves are the input tensors and roots are the output tensors. (View Highlight)
Internally, autograd represents this graph as a graph of Function objects (really expressions), which can be apply() ed to compute the result of evaluating the graph. (View Highlight)
(the .grad_fn attribute of each torch.Tensor is an entry point into this graph) (View Highlight)
the graph is recreated from scratch at every iteration (View Highlight)
Note: Calling backward() on a tensor will cause the computational graph on which it depends to be destroyed: all dependencies in the graph are discarded. This is a side effect.
to prevent reference cycles, PyTorch has packed the tensor upon saving and unpacked it into a different tensor for reading. Here, the tensor you get from accessing y.grad_fn._saved_result is a different tensor object than y (but they still share the same storage). (View Highlight)
Whether a tensor will be packed into a different tensor object depends on whether it is an output of its own grad_fn, (View Highlight)
The gradient computation using Automatic Differentiation is only valid when each elementary function being used is differentiable. (View Highlight)
Note: The upshot is that, even for non-differentiable functions, Autograd will try to find some reasonable approximation of the gradient if it is possible.
If the function is not a deterministic mapping (i.e. it is not a mathematical function), it will be marked as non-differentiable. (View Highlight)
Note: Setting requires_grad to False causes PyTorch to treat the tensor as a constant for the purpose of autograd. During backpropagation, no gradient of the loss with respect to this tensor will be computed.
This does not automatically ensure that the tensor will be treated as a constant by other code. There is nothing stopping the programmer from writing code that will mess with the tensor’s contents; nor is there anything stopping an optimizer from doing the same. In practice, though, reasonable optimizers (and engineers) will not do this. At least not on purpose.
Note that requires_grad=False has a nuanced effect if it is set on a tensor that depends on another for which requires_grad=True. In this case, no gradient with respect to the False tensor will accumulate during the backward pass. However, operations will still be tracked in the computational graph during the forward pass, because the gradient must flow through this tensor.
setting it only makes sense for leaf tensors (tensors that do not have a grad_fn, e.g., a nn.Module’s parameters). (View Highlight)
Note: requires_grad is only meaningful if the tensor is a leaf of the dependency graph, i.e., if nobody else depends on it
Note: Refer to the dependency graph diagram from the tutorial:
https://pytorch.org/tutorials/_images/comp-graph.png
The parameters of the model have no dependencies. The loss function depends on everything else.
This is because the dependency graph refers to the dependencies for the forward pass. During the backwards pass, the parameters depend on the loss function; i.e., the dependency graph is reversed.
To be contrasted with “no-grad mode” the default mode is also sometimes called “grad mode”. (View Highlight)
computations in no-grad mode are never recorded in the backward graph even if there are inputs that have require_grad=True. (View Highlight)
no-grad mode might be useful when writing an optimizer: when performing the training update you’d like to update parameters in-place without the update being recorded by autograd (View Highlight)
Note: In the tutorial, the only place where they use no_grad is in evaluating the test set at the end of an epoch.
If this were not done, any loss accumulated during inference against the test set would be treated as part of a forward pass. At the end of the first forward pass of the next epoch, the data would contribute to the gradient of the loss, allowing the model to learn from the test examples.
Inference mode is the extreme version of no-grad mode. (View Highlight)
Functionally, module.eval() (or equivalently module.train(False)) are completely orthogonal to no-grad mode and inference mode. How model.eval() affects your model depends entirely on the specific modules used in your model and whether they define any training-mode specific behavior. (View Highlight)
You are responsible for calling model.eval() and model.train() if your model relies on modules such as torch.nn.Dropout and torch.nn.BatchNorm2d that may behave differently depending on training mode, for example, to avoid updating your BatchNorm running statistics on validation data. (View Highlight)
In-place operations can potentially overwrite values required to compute gradients. (View Highlight)
Every in-place operation requires the implementation to rewrite the computational graph. (View Highlight)
Note: Calling backward() causes Autograd to calculate the gradient of the function leading to the current tensor (its grad_fn) with respect to each operation before it successively. When Autograd reaches a leaf tensor, it adds the computed gradient to its .grad property (which is initialized to zero). Gradients of intermediate nodes are typically discarded, though there are exceptions.
A side effect of calling backward() is that, unless the argument retain_graph is set to True, the computation graph is destroyed as a side effect.
The only idiomatic way to reset the leaf tensors’ gradients to zero is to call zero_grad() on an optimizer associated with them. That is, the tensor does not have a native way to reset its own gradient, which from an OO perspective is weird.
These two design decisions, destroying the graph as a side effect and coupling zero_grad to an external object, reflect prioritization of simplicity for PyTorch’s main use case over object-oriented purity.

{kind=link}